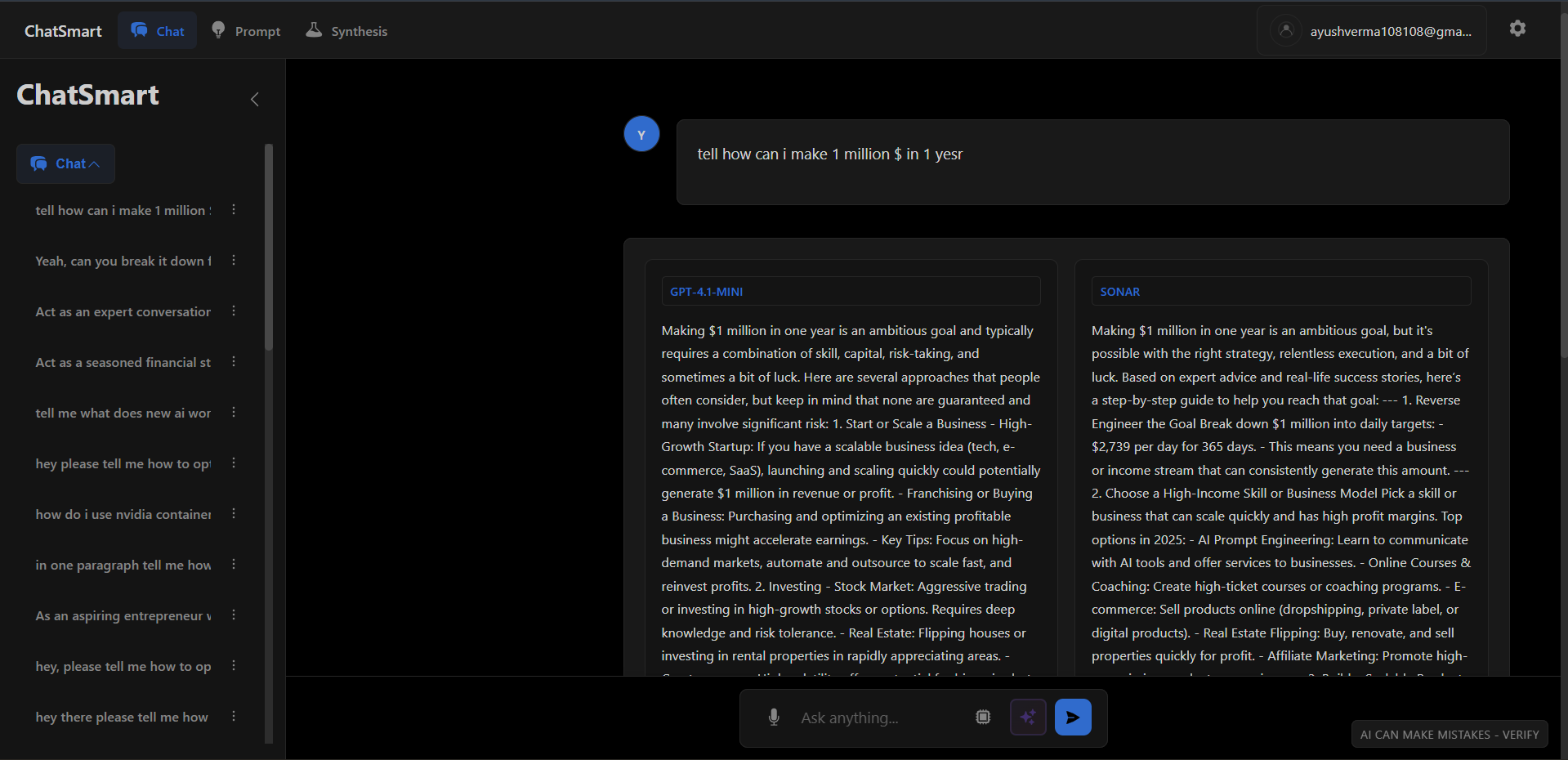
EvalArenaHead-to-Head Benchmarking Workbench
Beyond "Vibes" Based Eval
Most teams pick LLMs based on generic leaderboards (MMLU, HumanEval). But for specialized domains like Legal Contract Review or Medical Summarization, generic scores are meaningless.
**EvalArena** is a workbench for empirical selection. It allows me to run identical prompts across Gemini 1.5 Pro, Claude 3.5 Sonnet, and GPT-4o simultaneously, blind-vote on the outputs, and automatically score them using a rigorous rubric.
System Architecture
EvalArena operates as a multi-model orchestration layer, routing identical prompts to multiple providers and collecting responses in parallel. The judge LLM then scores each response using a rubric-based evaluation.
LLM-as-a-Judge: Rubric-Based Scoring
Instead of relying on subjective human voting alone, EvalArena uses GPT-4 as an automated judge with a structured rubric. This enables reproducible, scalable evaluation across hundreds of test cases.
1# Judge LLM Prompt Template with Rubric2SYSTEM_PROMPT = """3You are an expert evaluator for AI-generated responses.4Score the following response on a scale of 1-10 based on these criteria:561. **Accuracy** (0-3 points): Factual correctness, no hallucinations72. **Relevance** (0-3 points): Directly addresses the user's question83. **Clarity** (0-2 points): Well-structured, easy to understand94. **Completeness** (0-2 points): Covers all aspects of the question1011Provide:12- A breakdown score for each criterion13- A total score (0-10)14- 2-3 sentence reasoning1516Format your response as JSON:17{18 "accuracy": 3,19 "relevance": 2,20 "clarity": 2,21 "completeness": 1,22 "total": 8,23 "reasoning": "Response is factually correct but lacks depth..."24}25"""2627# Example evaluation call28async def judge_response(prompt: str, response: str, rubric: dict) -> EvalResult:29 judge_prompt = f"""30 **User Prompt:** {prompt}3132 **Model Response:** {response}3334 **Evaluation Rubric:** {json.dumps(rubric)}3536 Provide your scoring and reasoning.37 """3839 result = await openai.chat.completions.create(40 model="gpt-4o",41 messages=[42 {"role": "system", "content": SYSTEM_PROMPT},43 {"role": "user", "content": judge_prompt}44 ],45 response_format={"type": "json_object"},46 temperature=0.1 # Low temp for consistency47 )4849 return EvalResult.parse_raw(result.choices[0].message.content)
Why GPT-4 as Judge?
GPT-4 shows highest correlation with human preferences in academic studies. We use structured JSON output mode for reliable parsing.
Temperature = 0.1
Low temperature ensures consistent scoring across runs. Critical for reproducible benchmarks.
Custom Rubrics
Rubric weights can be adjusted per domain (e.g., legal docs prioritize accuracy 50%).
Parallel Model Execution
All three models are called simultaneously using async/await patterns. This reduces total wait time from ~15 seconds (sequential) to ~5 seconds (parallel, limited by slowest model).
1import asyncio2from typing import List34async def call_model(model_name: str, prompt: str) -> ModelResponse:5 """Call a single model and track timing/tokens"""6 start = time.time()78 if model_name == "gemini":9 response = await gemini_client.generate_content(prompt)10 elif model_name == "claude":11 response = await anthropic_client.messages.create(12 model="claude-3-5-sonnet-20241022",13 messages=[{"role": "user", "content": prompt}]14 )15 elif model_name == "gpt4":16 response = await openai.chat.completions.create(17 model="gpt-4o",18 messages=[{"role": "user", "content": prompt}]19 )2021 latency = time.time() - start2223 return ModelResponse(24 model=model_name,25 text=response.text,26 latency_ms=latency * 1000,27 tokens=response.usage.total_tokens,28 cost_usd=calculate_cost(model_name, response.usage)29 )3031async def arena_compare(prompt: str) -> ArenaResult:32 """Execute all models in parallel"""33 models = ["gemini", "claude", "gpt4"]3435 # Run all models concurrently36 responses = await asyncio.gather(*[37 call_model(model, prompt) for model in models38 ])3940 # Anonymize for blind voting (shuffle identifiers)41 shuffled = random.sample(list(enumerate(responses)), len(responses))4243 return ArenaResult(44 responses={f"Model {chr(65+i)}": resp for i, (_, resp) in enumerate(shuffled)},45 identity_mapping={f"Model {chr(65+i)}": models[orig_idx] for i, (orig_idx, _) in enumerate(shuffled)}46 )
Performance Metrics (Typical)
1. The "Arena" Mode
Inspired by LMSYS. Two models fight anonymously. You vote for "Model A" or "Model B". Only after voting are the identities revealed. This eliminates brand bias.
2. Token Observability
Real-time tracking of Token/Sec and Cost per Query. Often, I find that Phi-3-medium ($0.50/1M tokens) is "good enough" for tasks where I assumed I needed GPT-4 ($5.00/1M).
3. Synthesis Engine
Can't decide? The "Synthesis" button fuses the best parts of all three model outputs into a single, superior answer using a recursive summarization capability.
This tool is my "daily driver" for AI engineering. It's how I choose the right model for every client problem.
Watch Demo