Production-Ready Statistical Arbitrage Engine
StatArb Execution Engine: From Research to Production
Media & Demos
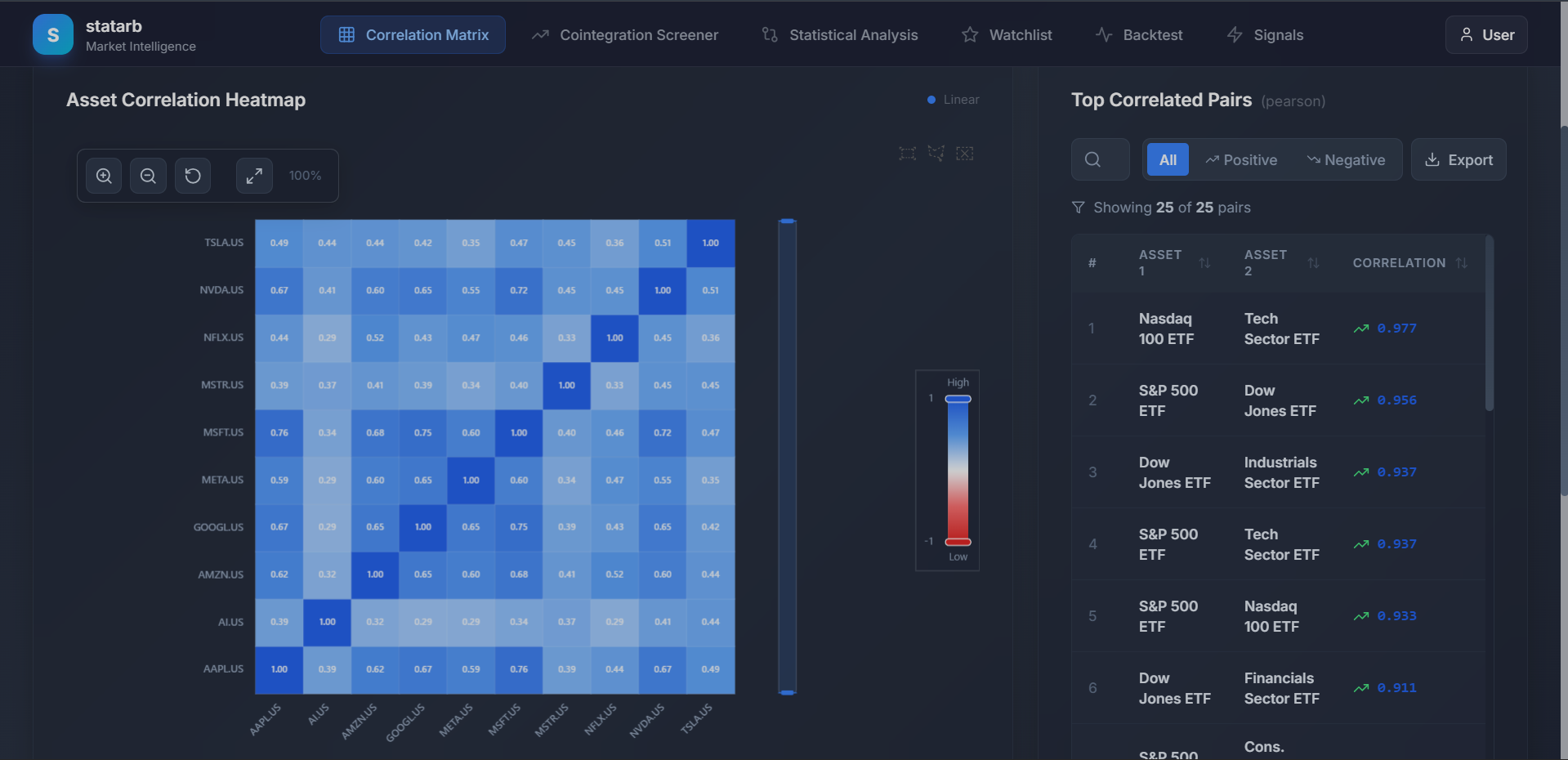
Asset Correlation Heatmap
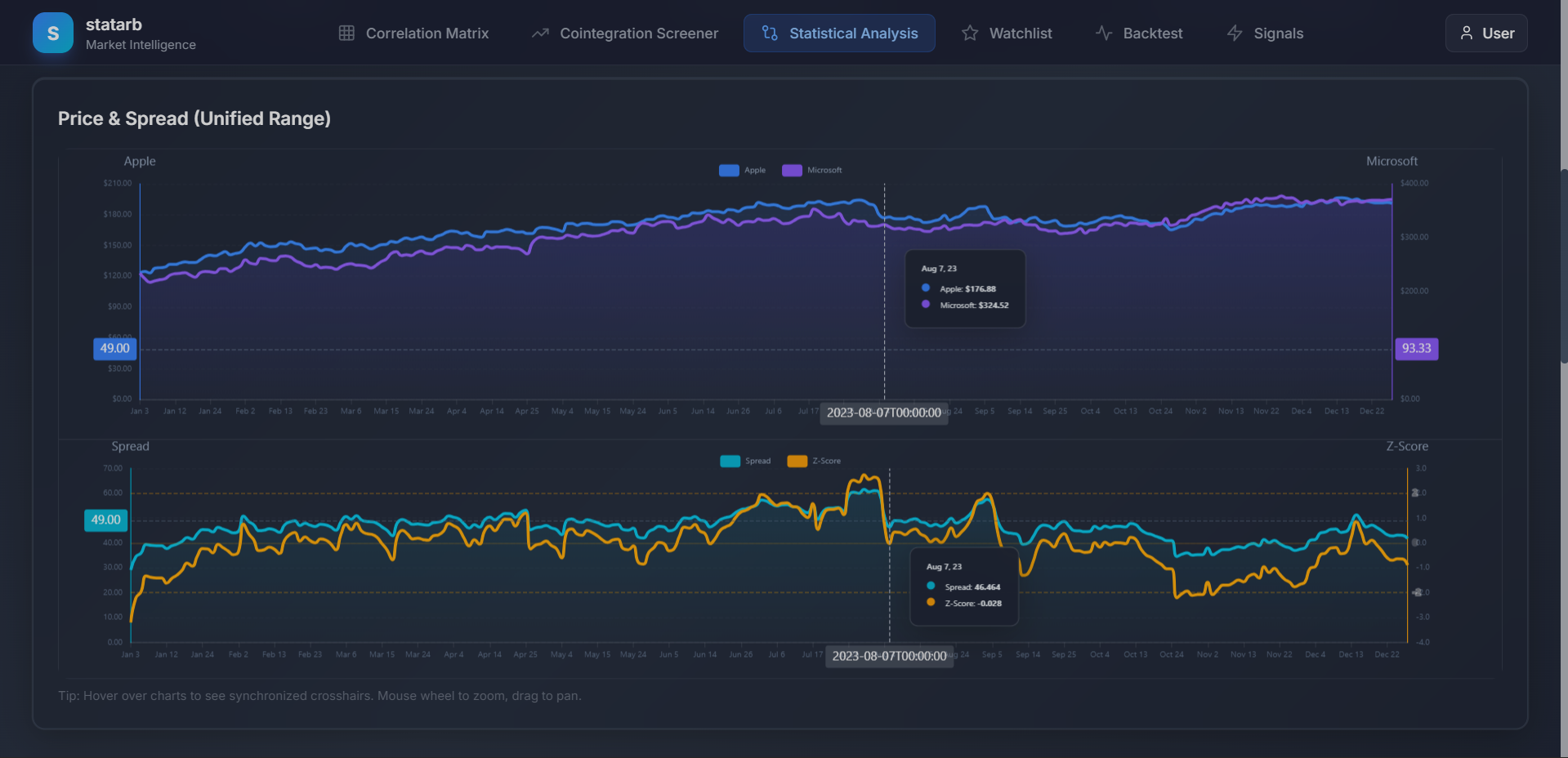
Price & Spread Analytics
Role
Founder / Quant Developer
Period
2025
Category
trading
Overview
High-frequency bridge connecting Quantitative Rigor (Cointegration, GARCH) with Agentic Reasoning. Features a custom 'Supabase Shim' for local TimescaleDB performance (<10ms), Tiered Prediction Councils, and a Hexagonal Architecture ensuring 100% testability.
Key Highlights
- Supabase Shim: Lightweight proxy routing SDK calls to local TimescaleDB (<10ms latency)
- Hexagonal Architecture: Strict Ports & Adapters for valid runtime switching (Postgres/Memory)
- Tiered Prediction Councils: Statistical models -> ML Ensembles -> LLM Debate
- Resilient Orchestration: Circuit Breakers for LLM providers (Gemini -> Claude -> OpenAI)
- Full observability with Prometheus metrics and health checks
- Request temporary access to explore the platform
Tech Stack
Summary
On-page overviewThis is a concise summary of the challenges, solution, and outcome for this project. Use the Case Study button above for the full deep dive.
The Problem
The 'Latency-Reliability Paradox'. Early reliance on cloud SDKs introduced unacceptable external latency (~150ms). Furthermore, trading requires speed, but ML training/inference (AutoGluon) is CPU-bound and blocking. I needed a system that was sub-10ms fast but smart enough to debate macro narratives without hanging the event loop.
The Solution
1. Infrastructure Pivot (The 'Supabase Shim'): Engineered a lightweight proxy mimicking cloud SDK syntax to route queries to local TimescaleDB hypertables, dropping read latency to <10ms without rewriting ingest scripts. 2. Hexagonal Architecture (DDD): Strict Ports & Adapters pattern with Factory-based dependency injection. Allows valid runtime switching between PostgresAdapter (Production), MemoryAdapter (Unit Tests), and JSONLAdapter (Audit). 3. Resilient Orchestration: Implemented Tiered Prediction Councils (Statistical Models -> ML Ensembles -> LLM Debate) and Circuit Breakers for LLM providers (Gemini 1.5 Pro -> Claude 3.5 Sonnet -> OpenAI o1) to ensure 99.99% uptime.
The Outcome
A production-grade engine where latency dropped by 93% (<10ms). The Circuit Breaker architecture navigated multiple API outages without interruption. Adding new brokers (e.g., IBKR) now takes <48 hours via the BrokerPort interface. This is not a bot; it is Google-standard software hygiene applied to crypto markets.
Team & Role
Solo build applying strict DDD and Google-standard engineering principles.
What I Learned
This project deepened my understanding of Python and FastAPI (Async) and reinforced best practices in system design and scalability. I gained valuable insights into production-grade development and performance optimization.