RAG-IntelligenceDocument Intelligence Pipeline
A production-oriented RAG workspace where every dashboard metric is backend-generated and every query follows a real retrieval stack. No mocked numbers, no placeholder pipelines.
Problem Framing
Most RAG demos stop at "answer quality looks fine" without proving how retrieval is behaving. This project targeted an architecture where ingestion, retrieval, and evaluation are all production-observable.
The target corpus was ArXiv ML literature, but the ingestion router was intentionally format-agnostic so the same pipeline can process PDF, HTML, JSON, CSV, text, and OCR-routed images.
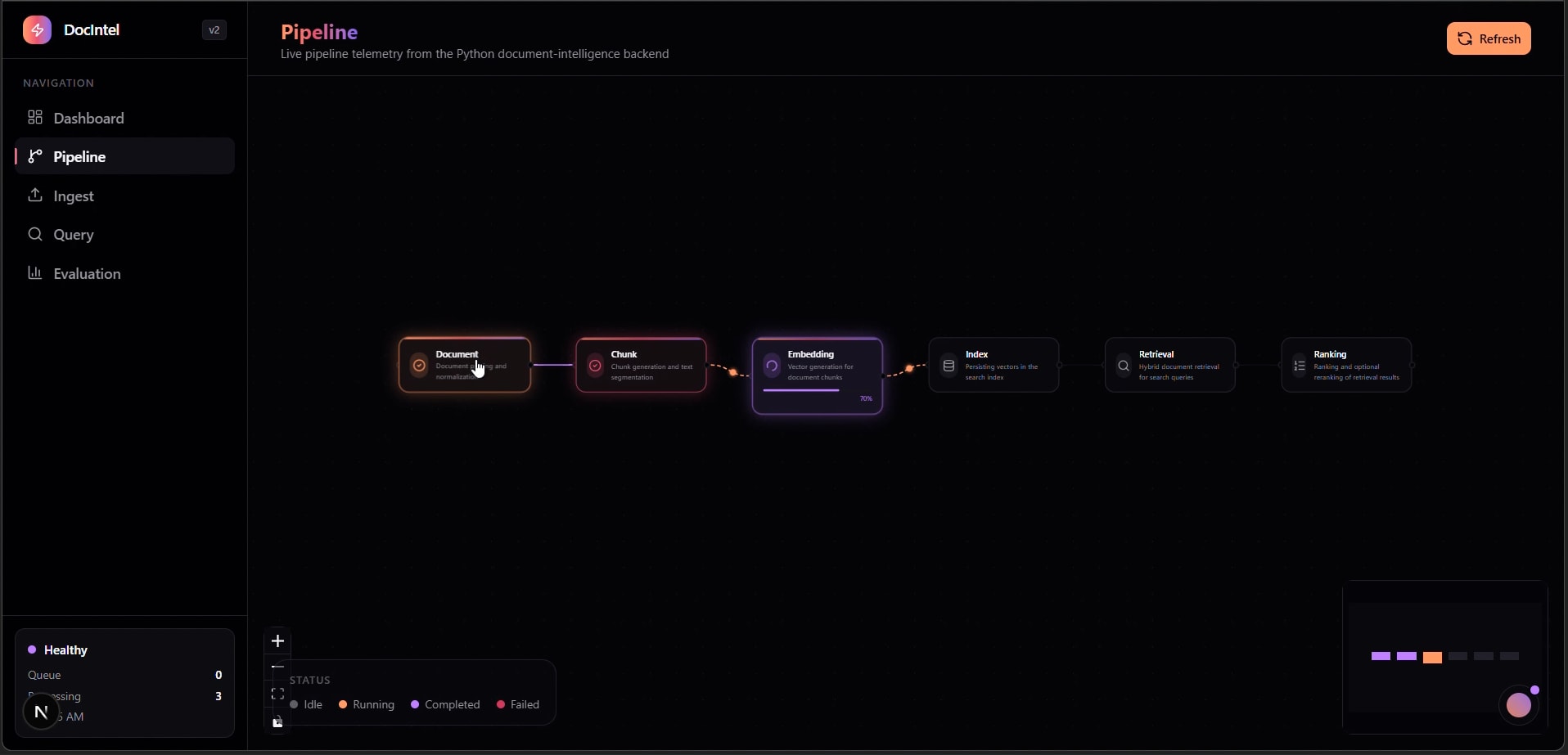
RAG Pipeline Architecture
The dashboard calls FastAPI directly. Ingestion writes to SQLite metadata + FAISS index, while retrieval runs a three-stage hybrid process with controllable reranking costs.
Three-Stage Retrieval Flow
Dense and sparse signals are normalized and merged, then promoted from chunk to document relevance, and finally reranked with a cross-encoder on the top candidate slice only.
Runtime Evidence from Local Pipeline Logs
This system narrative is backed by captured ingestion and query logs from the local ArXiv corpus runs. Index growth, embedding throughput, and per-stage retrieval latency were all observed in execution traces.
Ingestion Scale
- • FAISS/BM25 index repeatedly rebuilt as corpus expanded.
- • Logged growth to 3,919 indexed chunks in one captured run.
- • Embedding bursts ranged from 37 to 217 chunks depending on source file structure.
Latency Trace Sample
- • Query path captured as embed=0.011s, faiss=0.004s, total=0.016s.
- • Stage-level timings exposed to API consumers, not hidden behind a single number.
- • Cost controls applied by reranking only top 10% candidate docs.
Execution Portability
- • FAISS runtime loaded AVX2 and AVX512 variants depending on host capabilities.
- • SQLite + local file state enabled deterministic local reruns.
- • Telemetry endpoints made regression checks repeatable across sessions.
Ingestion Pipeline
- • File routing by source type (.pdf/.html/.json/.csv/.txt/.md/image OCR).
- • 600-token chunks with 100-token overlap (semantic chunking optional).
- • BAAI/bge-base-en-v1.5 embedding batches (size 32) into FAISS flat index.
Hybrid Retrieval Design
- • Stage 1: FAISS + BM25 merged via min-max normalization and 0.7/0.3 weighting.
- • Stage 2: document-level aggregation from top chunk matches with log length normalization.
- • Stage 3: cross-encoder reranking on top 10% docs for tractable latency.
Telemetry & Evaluation
- • Query responses expose decomposed latency, not single opaque response time.
- • Manual rerun endpoint recalculates metrics from backend truth for honest dashboards.
- • Precision@K and topic-level breakdowns drive retrieval tuning decisions.
Key Engineering Trade-Off
FAISS flat indexing was chosen for exact nearest-neighbor behavior at current scale. The system keeps index-type configurable so scaling to IVF/HNSW is a configuration transition, not an architectural rewrite.
Failure Modes Explicitly Handled
- • Dense-only retrieval drift on keyword-heavy queries mitigated with BM25 fusion.
- • Chunk-level score spikes mitigated via document aggregation + length normalization.
- • Reranker cost blowups controlled by promoting only top candidate slice.
Operational Loop
- • Ingest → evaluate → retune runs are closed by manual metric rerun endpoints.
- • Dashboard metrics are backend-computed snapshots, not frontend approximations.
- • Retrieval tuning decisions are documented against Precision@K and topic-level deltas.
Outcome
RAG-Intelligence delivers an evaluation-driven retrieval platform where architecture choices are validated through telemetry and repeatable metrics, not by anecdotal output quality.
What Was Built (April 8, 2026)
- • End-to-end ingest/retrieve/evaluate document intelligence service with real backend telemetry.
- • Hybrid retrieval and reranking pipeline with tunable weighting and rerank scope controls.
- • SQLite + FAISS local state model for deterministic development and reproducible evaluations.
- • Dashboard-first operations view for ingestion state, retrieval behavior, and metric reruns.