DocIntel v2 — Document Intelligence Platform
End-to-end RAG pipeline with live ingestion, retrieval, and evaluation
Media & Demos
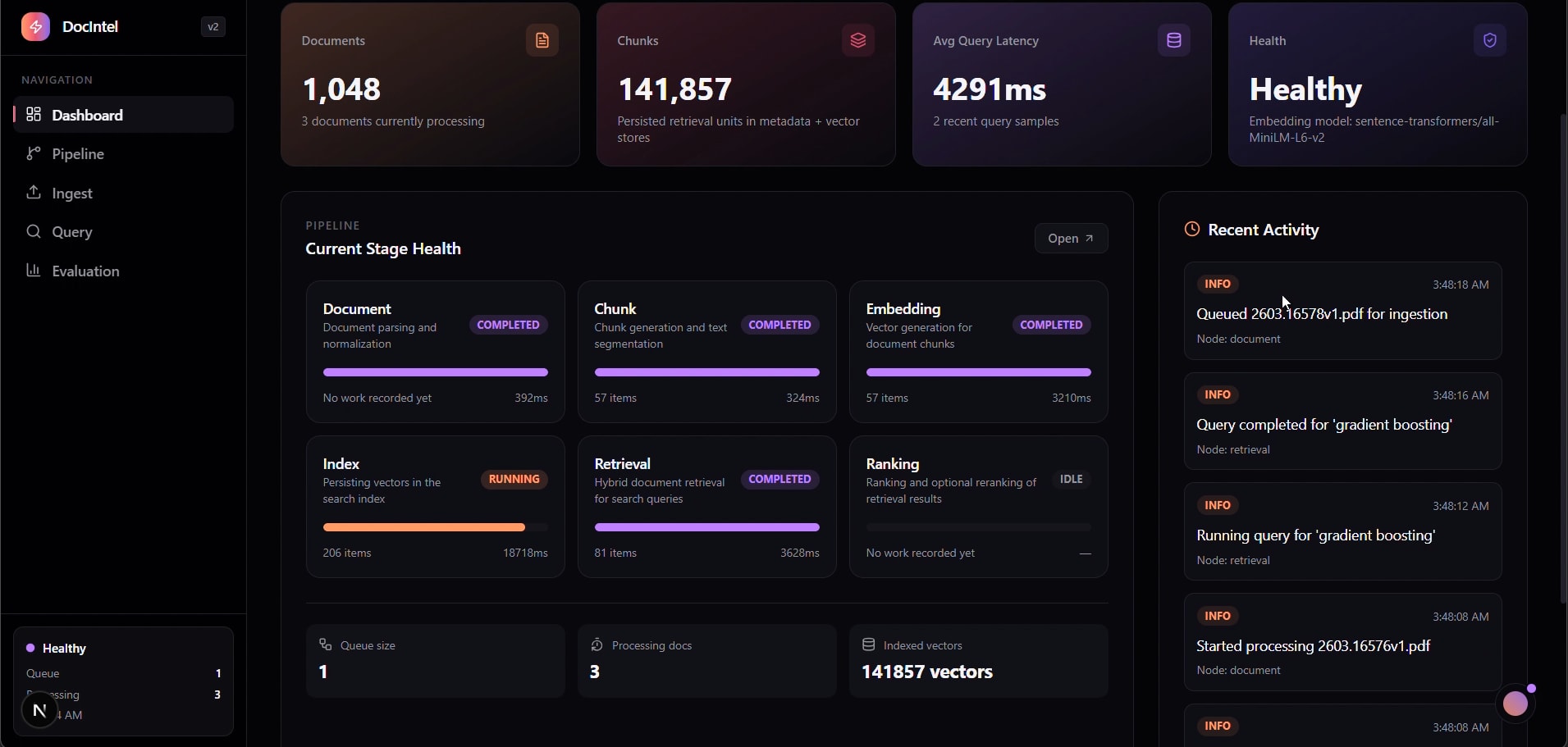
Dashboard — Pipeline Health & Metrics
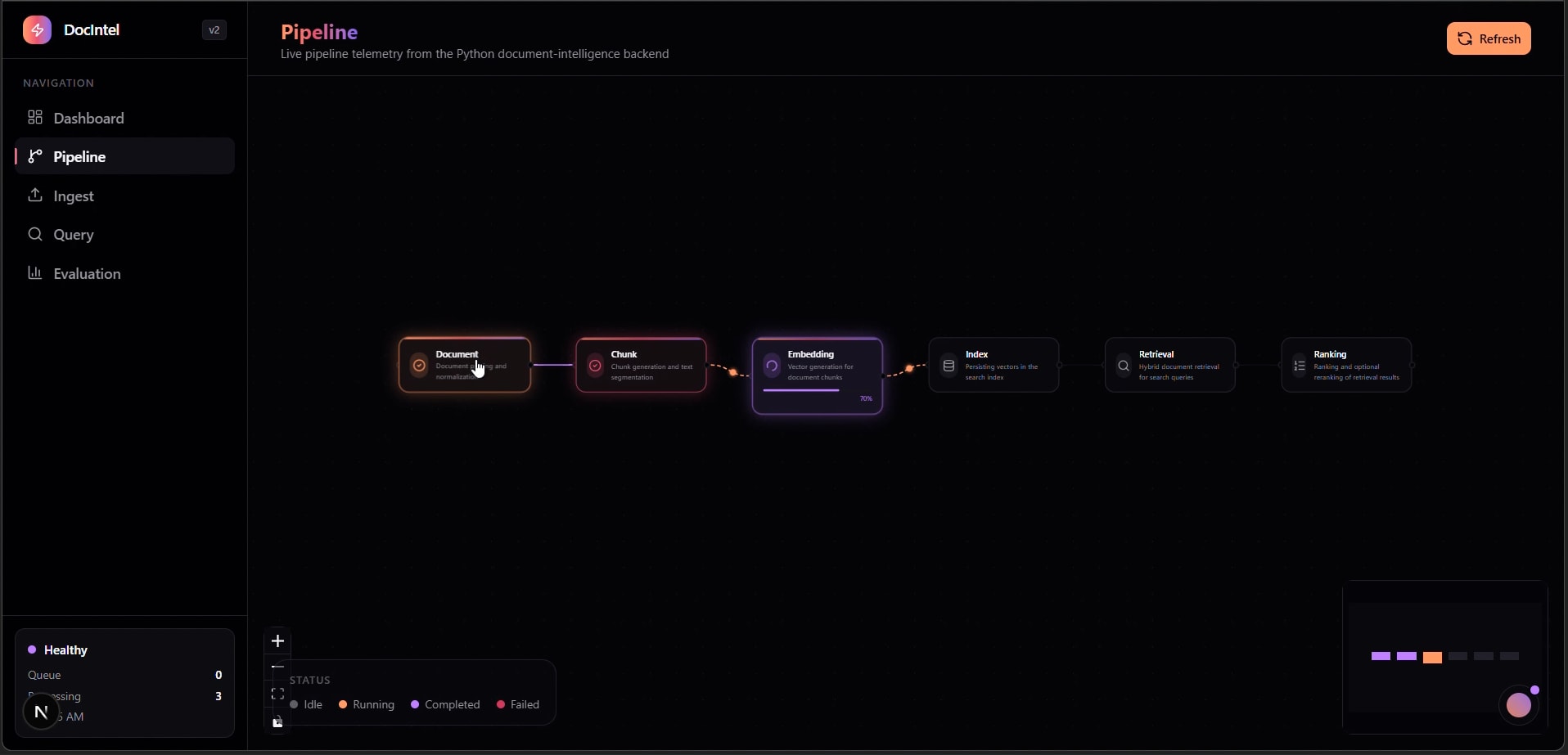
Pipeline — Live Stage Telemetry
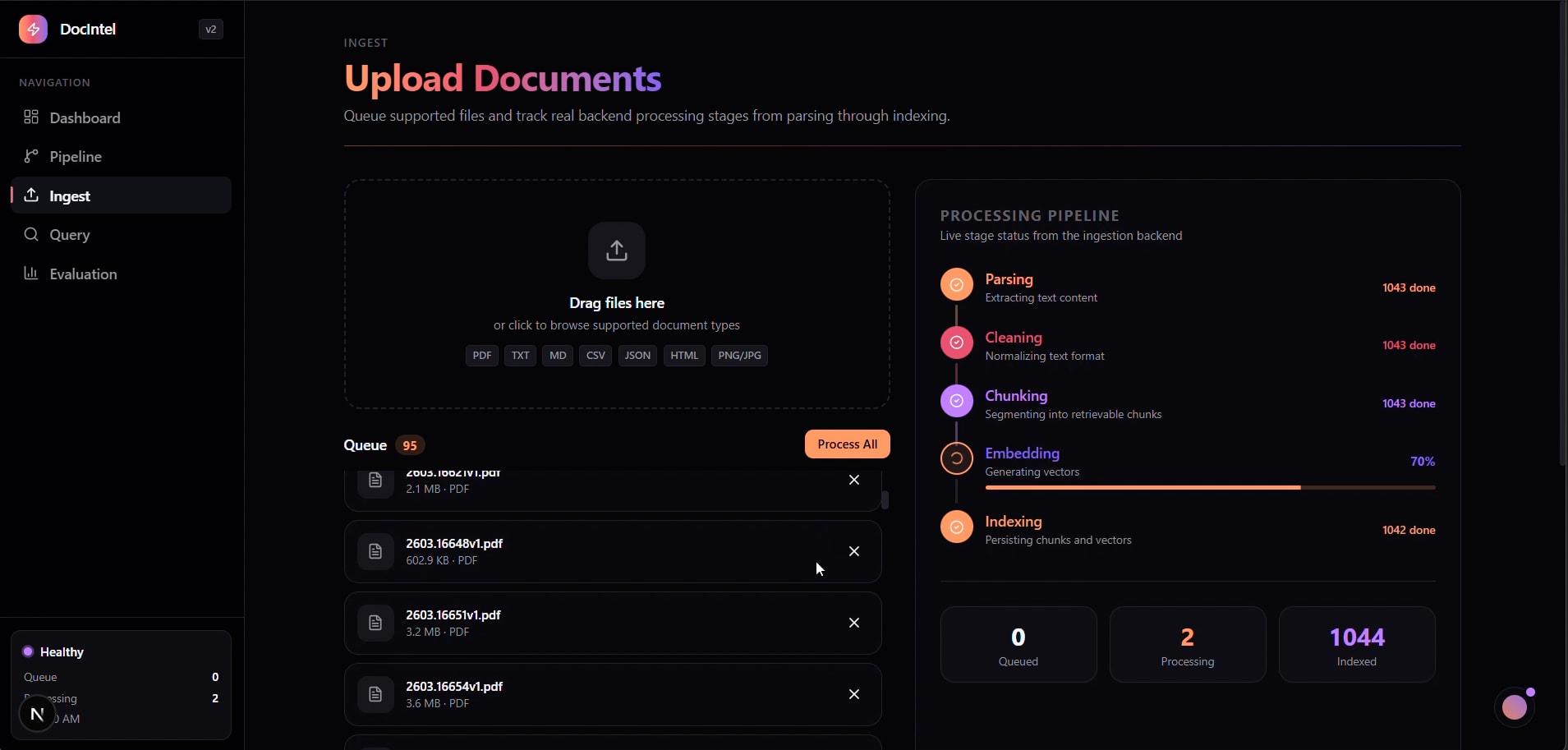
Ingest — Document Upload & Queue
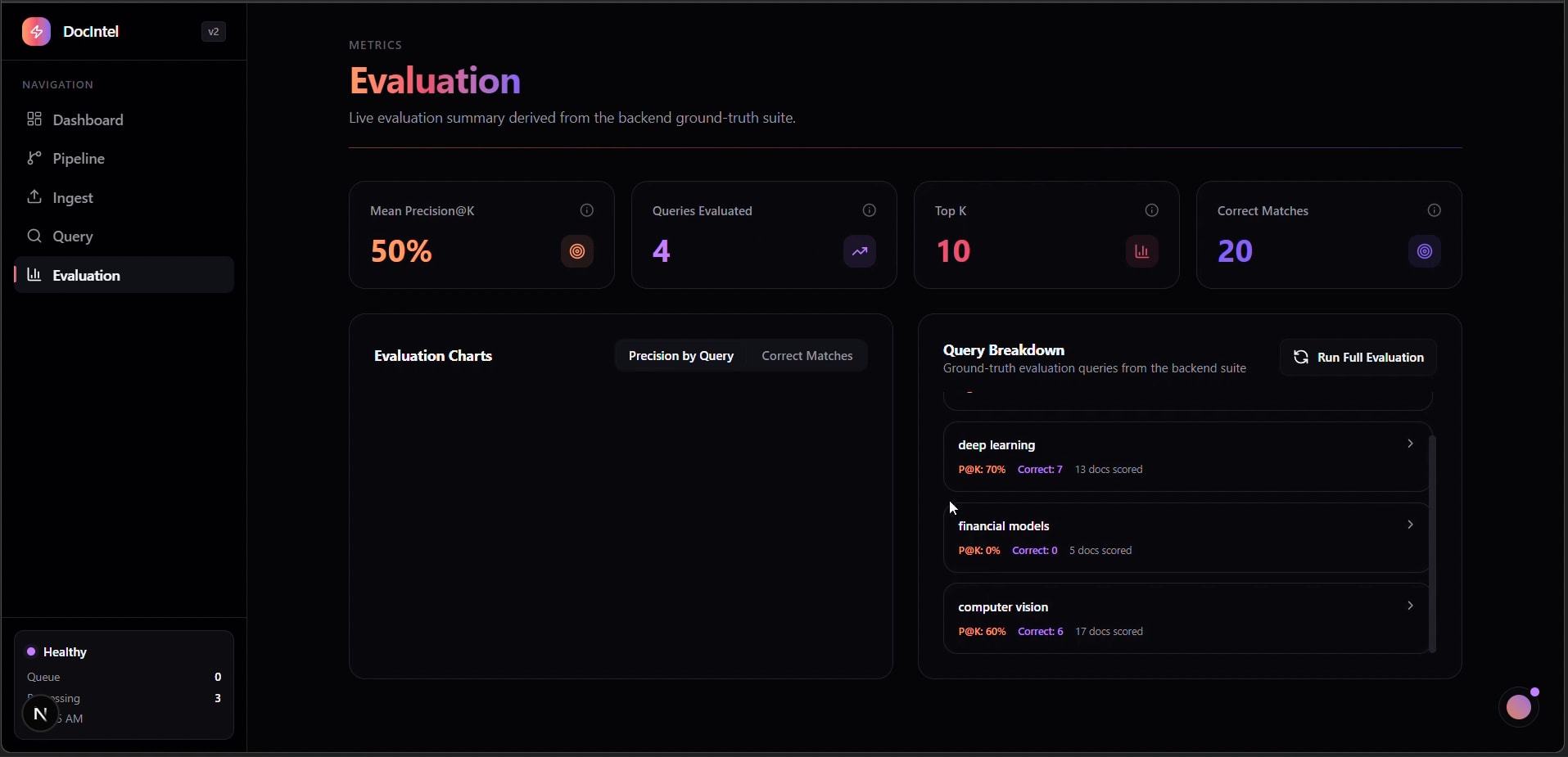
Evaluation — Precision@K & Query Breakdown
DocIntel Platform Demo
Role
AI Lead & Full-Stack Engineer
Period
2026
Category
ai
Overview
A full-stack document intelligence platform that operationalizes the RAG lifecycle: ingestion, parsing, chunking, embeddings, indexing, retrieval, and ranking. It exposes stage-level telemetry, retrieval evaluation, and index health so RAG quality can be measured rather than assumed.
Key Highlights
- 6-stage processing pipeline: Document → Chunk → Embedding → Index → Retrieval → Ranking
- Live pipeline telemetry with stage-level status, throughput, and latency visibility
- 141,857 indexed vectors across 1,048 processed source documents
- Hybrid retrieval path with optional reranking for higher answer relevance
- Ground-truth evaluation suite with Precision@K and per-topic breakdown
- Operational dashboard for queue depth, ingestion health, and index status
Tech Stack
Links
Summary
On-page overviewThis is a concise summary of the challenges, solution, and outcome for this project. Use the Case Study button above for the full deep dive.
The Problem
Most RAG implementations provide answers but little observability. Without stage-level telemetry and evaluation baselines, teams cannot diagnose retrieval failures or quantify quality regressions.
The Solution
Built an end-to-end RAG operations layer where each pipeline stage is measurable, query behavior is inspectable, and retrieval quality is benchmarked through a reproducible Precision@K suite.
The Outcome
Delivered a production-grade RAG platform processing 1,048 documents into 141,857 vectors with transparent health instrumentation and evaluation-first retrieval workflows.
Team & Role
AI Lead & Full-Stack Engineer — owned architecture, retrieval/eval design, and platform implementation.
What I Learned
RAG quality improvements came from observability discipline, not model swaps. Instrumenting chunk quality, retrieval depth, and topic-level precision made it possible to iterate using evidence instead of intuition.