EvalArena: Model Benchmarking Workbench
Head-to-head evaluation harness for specialized domain tasks
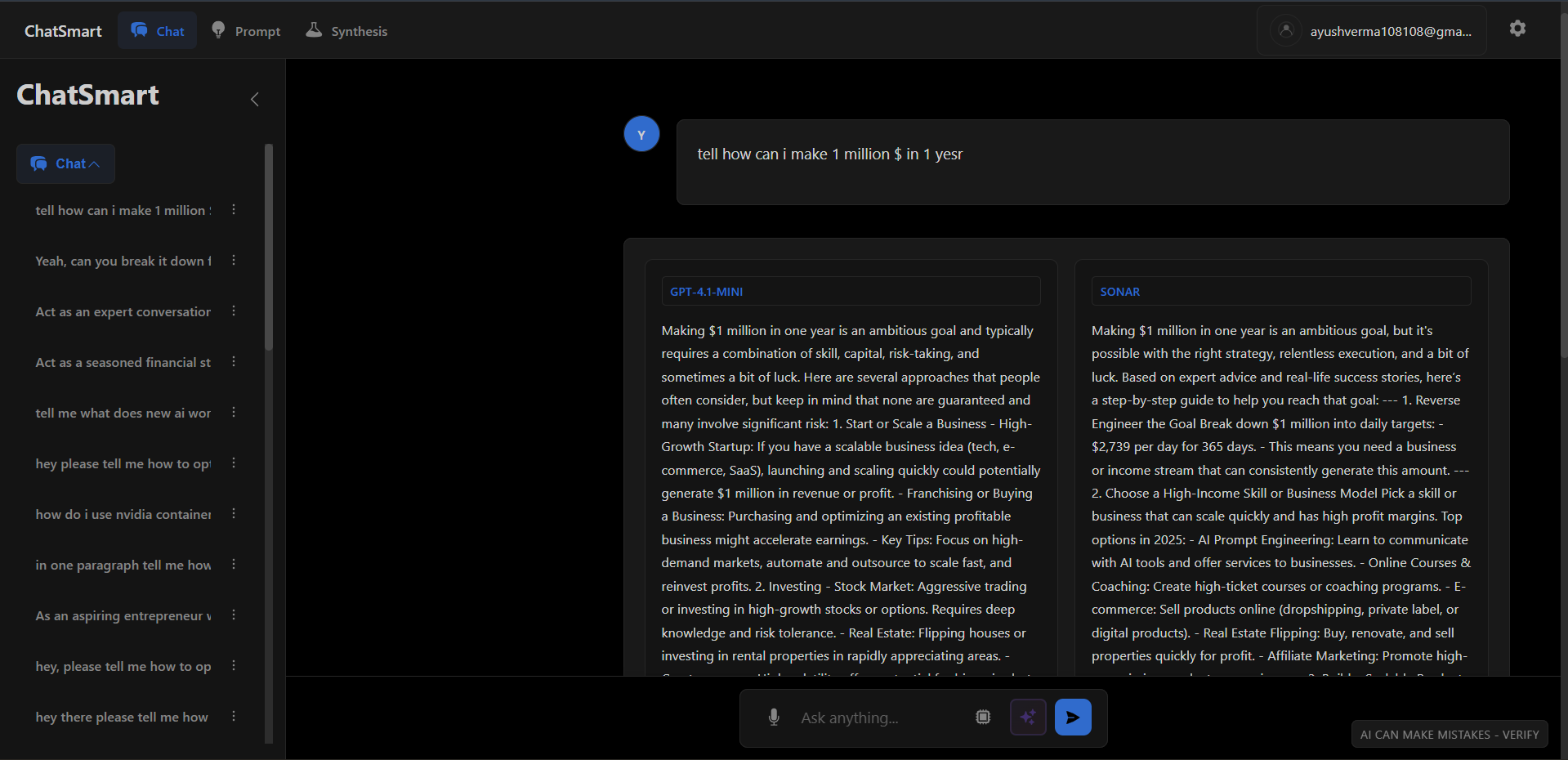
Media & Demos
Prompt Engineering Flow
Role
Creator / Full-Stack Engineer
Period
2025
Category
experiment
Overview
A benchmarking workbench for evaluating LLM performance on domain-specific tasks. Features a model arena for side-by-side comparison, automated scoring pipelines, and detailed observability into token usage and latency.
Key Highlights
- Multi-model support with OpenAI GPT-4 and Perplexity Sonar adapters
- Advanced synthesis engine with token-frequency, summarization, and score-based blending
- Reasoning mode with step-by-step thinking visualization
- Production-ready auth with JWT, rate limiting, and response caching
- Full test coverage and comprehensive error handling
Tech Stack
Summary
On-page overviewThis is a concise summary of the challenges, solution, and outcome for this project. Use the Case Study button above for the full deep dive.
The Problem
Choosing the right LLM for specialized tasks (e.g., legal, medical, coding) is guesswork without empirical data. Generic benchmarks (MMLU) don't reflect custom domain performance.
The Solution
Built a side-by-side evaluation harness where users input a prompt and blindly vote on outputs from multiple models (Gemini, Claude, GPT-4). Includes automated scoring via 'Judge' models.
The Outcome
Identified that small models (Phi-3) outperformed GPT-4 on specific extraction tasks, saving 90% on inference costs for a client project.
Team & Role
Solo Engineer. Designed the evaluation methodology and built the entire full-stack application.
What I Learned
This project deepened my understanding of Python 3.11+ and FastAPI and reinforced best practices in system design and scalability. I gained valuable insights into production-grade development and performance optimization.